

OCR Variables
(Available from version 7.2 onwards.)
Use the OCR (Optical Character Recognition) variables to capture text and other information from PDF and image files, for example, scans of forms completed by customers and employees by hand.
The following main object types are provided:
-
Advanced PDF Object: For character recognition from PDF files where the text is stored as an image and not digitally as text (which can instead be retrieved using the functions in the PDF Documents built-in service.)
-
Advanced Picture Object: For character recognition from image files.
The following additional object types are provided to receive information returned by the methods of the Advanced PDF and Advanced Picture objects:
-
OCR Suspicious Data Object: Stores information about a single instance of suspicious data in a PDF file or image.
-
OCR Word Data Object: Stores lists of words found using various methods of Advanced PDF Object and Advanced Picture Object variables.
Install NiCE Advanced OCR
To use the OCR variable types and their methods, you must first install NiCE Advanced OCR.
See Install NICE Advanced OCR.
Advanced PDF Object
Create an Advanced PDF Object variable to capture the text contents of a PDF file using an OCR engine.
The Advanced PDF Object type and its methods are intended for retrieving text from PDF files that contain images of text, for example, scanned forms that have been completed by hand.
For retrieving text from PDF files in which all data is saved as text, for example, PDF forms that were completed electronically, use the functions in the PDF Documents built-in service instead.
-
Text that is stored digitally
PDF files that contain digital text are usually created by converting files from other formats, such as MS Word files, into PDF files.
When opened in a PDF reader such as Acrobat Reader, it is possible to select and copy digital text, as below.

The PDF Documents built-in service allows you to capture digital text data.
PDF forms are PDF files that contain digital text as well as special fields that allow, for example, customers to fill in their information. The information captured in the form fields is stored digitally.
Shown below is part of a PDF form. The text the customer entered into the two Name fields is stored as digital text.
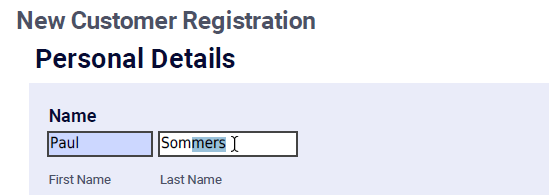
The PDF Documents built-in service allows you to capture information entered into PDF form fields. Functions are also provided to allow you to enter text into PDF form fields.
-
Text that is stored as an image
When a printed page is scanned to create a PDF file, the page is stored as an image within the PDF file, and the text on that page is treated as part of the image. The PDF file does not "know" that some of the dots on the page form text.
When opened in a PDF reader such as Acrobat Reader, it is not possible to select individual texts.
Shown below is a scanned membership form. The entire page is stored in the PDF file as a single image. It is not possible to select texts on the page; you are only able to select areas of the page to copy as images.

Text stored in this way can be recognized and retrieved using OCR objects. The PDF Documents built-in service does not allow you to capture scanned text data.
Properties
|
Property |
Type |
Description |
Writable |
|---|---|---|---|
| Block Count | Number | The number of OCR blocks on the Active Page of the document | No |
| File Name | Text | The full path to the PDF file | Yes (Use Assign) |
| Active Page | Number | The page number of the page in the PDF file from which to read data. The default value is 1. | Yes (Use Assign) |
| Languages | Text | The expected language(s) of the text, passed as an input to the OCR engine to improve text recognition. The default is English. |
Yes (Use SetLanguages) |
| Table Count | Number | The number of tables on the Active Page of the PDF file | No |
| Page Count | Number | The number of pages in the PDF file | No |
| OCR Mode | Text | The OCR mode to be used by the OCR engine |
Yse (Use SetOCRMode) |
Example Files
An example workflow is presented for every method listed below.
All examples are based on the PDF JS_MembershipForm.PDF.
The File Name property of the Advanced_PDF variable is set by default to c:/temp/JS_Membeshipform.pdf.
To view the sample project:
-
Download the ZIP file of the sample project here.
-
Copy the zip files to the folder%AppData%/Nice_Systems/AutomationStudio/Projects.
-
Copy the pdf file to the folder c:/temp.
-
Open the project OCR_Examples in Automation Studio. Each workflow is named with the name of the function it demonstrates.
Methods
Creates an image of the active page of the PDF file. Use the Assign function to store that image in an Advanced Picture Object.
Parameters
This method does not have any parameters.
Returns
Returns an Advanced Picture Object.
Example
The workflow below:
-
Sets the active page to page 1.
-
Converts the active page from the PDF to an image stored in the variable Advanced_Picture (of type Advanced Picture), using the Covert Page to Image method.
-
Saves the image stored in Advanced_Picture to a PNG image file at c:/temp/out_page1.png.
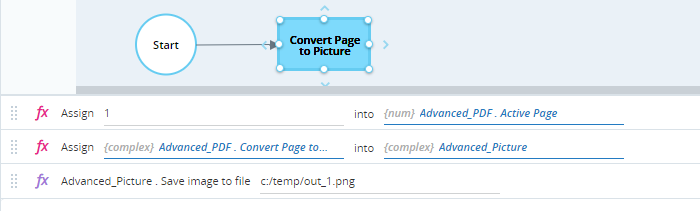
When executed, the Advanced_Picture variable is populated.
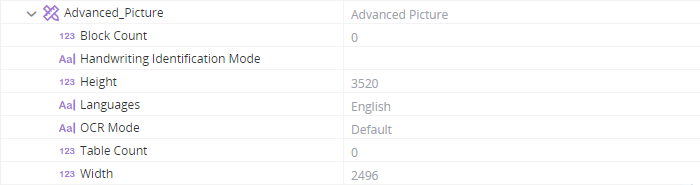
The file at c:/temp/out_page1.png is created and contains an image of the page.
Creates an image of a specified area of the active page of the PDF file. Use the Assign function to store that image in an Advanced Picture Object.
The size and location of the rectangle to convert to an image is specified using a Screen Element Rectangle variable. The dimensions specified in the properties of the screen element rectangle are specified in terms of "dots" and are thus affected by the DPI (dots per inch) of the PDF file. For example, if the PDF file has a DPI of 300:
-
Specifying the width parameter as 600 effectively sets the width of the image extracted to be 2 inches (600 dots / 300 dots-per-inch = 2 inches).
-
Specifying the width parameter to be 2481 effectively sets the width of the image extracted to be 8.75 inches (2481 / 300 dots-per-inch = 8.75 inches), which is the full width of an A4 page.
The width of the extracted image in pixels will be equal to the value of the width property of the screen element rectangle. Similarly, the image's height in pixels corresponds to the height property of the screen element rectangle.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the area to extract (specified by its left and top properties), and the size of the area to extract (specified by its height and width properties) |
Returns
Returns an advanced picture object.
Example
A country club membership form includes a space for the applicant's signature. The country club would like to capture that signature.

To specify the location of the rectangle, a screen element rectangle variable must be created and populated. The following parameters must be specified:
To get these measurements, it is useful to first extract the entire page as an image, save the image as an image file, and take the measurements from that file. See the example for Convert Page to Picture.
Instructions to get the measurements are shown below:
-
Open the image in Microsoft Paint.
-
Select the full area allocated for the signature.

-
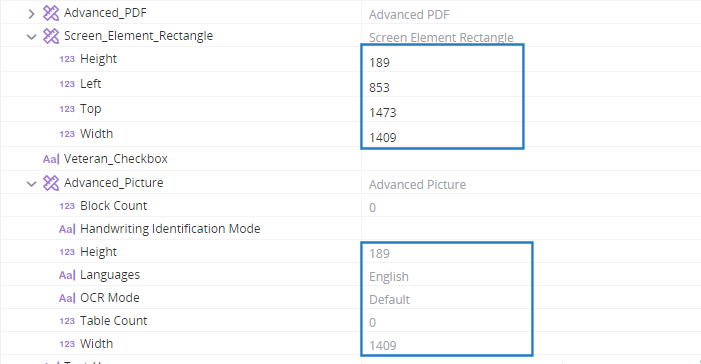
Get the height and width from the info bar at the bottom. In this case, the Width is 1409 and the Height is 189.

-
-
Point at the top left corner of the area for the signature and read the location measurements from the info bar. In this case, Top is 1473 and Left is 853.

The workflow below:
-
Sets the active page to page 1.
-
Sets the properties of the Screen_Element_Rectangle variable (of type Screen Element Rectangle) so as to create a rectangle around the form's signature area.
-
Extracts the rectangle as an image using the Extract Rectangle as Image method, storing the image in the Advanced_Picture variable (of type Advanced Picture).
-
Saves the image stored in the Advanced_Picture variable to the PNG image file at c:/temp/out_signature using the Save Image to File method.
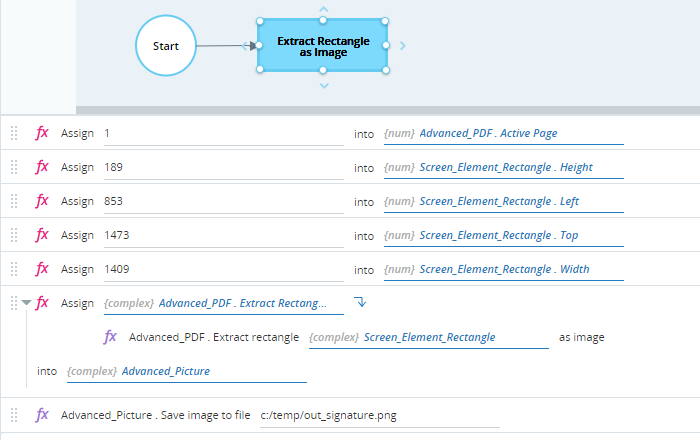
When executed, the Advanced_Picture and Screen_Element_Rectangle variables are populated as expected. Note that the Height and Width dimensions of the Advanced_Picture variable are the same as those we set for the rectangle.
The file at c:/temp/out_signature.png is created as expected.

Retrieves the state of the checkbox in a specified rectangle on the active page of the PDF.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the checkbox (specified by its left and top parameters), and the size of that area (specified by its height and width paramaters) |
Returns
Returns a text value: Checked, NotChecked, Corrected (was checked but then corrected), or Not Recognized. If OCR is not installed, NotDetected is returned.
Retrieves the locations of all cells in a table. The first table on the page is numbered 1. The locations are returned as elements in a list of type Screen Element Rectangle. The locations of the cells in the first row are returned first in the list, followed by the cells in the second row, and so on.
Note that:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.

-
The table does not have to have the same number of columns in each row.
Returns
Returns a list of type Screen Element Rectangle. Each cell is represented by one element in the list.
Example
The example PDF file includes the following table:

The workflow below:
-
Sets the active page to page 1.
-
Retrieves the locations of all cells in the first table on the page and stores them in the List_of_Screen_Element_Rectangles variable (a list of type Screen Element Rectangle), using the Get Locations of Table Cells method.
For demonstration purposes, the workflow then:
-
Stores the image defined by the first screen element rectangle to the Advanced_Picture variable using the Extract Rectangle as Image method.
-
Saves the image in the file at c:/temp/out_tablecell.png.
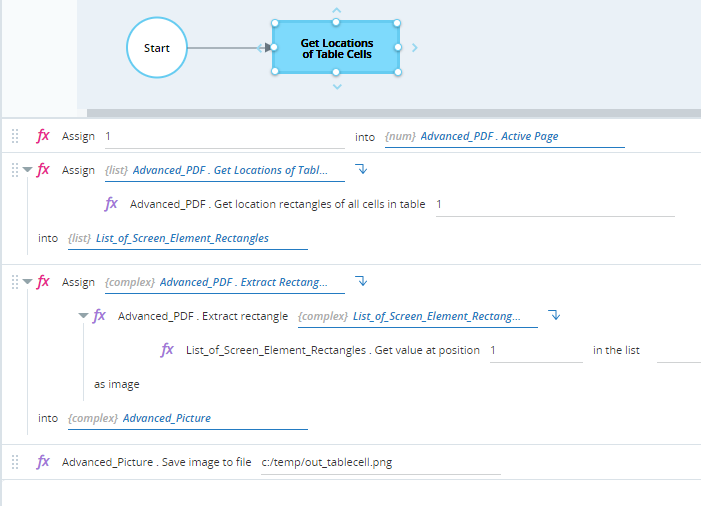
When executed, the locations of all 14 cells in the table are stored in the List_of_Screen_Element_Rectangles variable, each as a separate element.
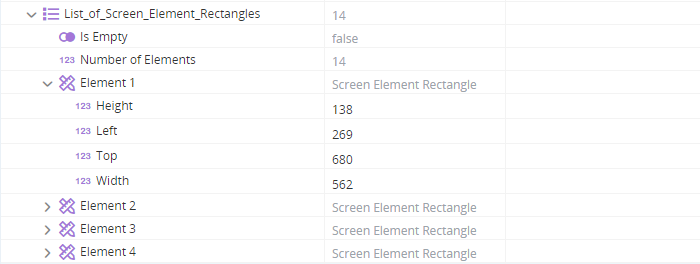
The image file c:\temp\out_tablecell.png is saved and shows the first cell in the table.

Retrieves a list of all locations of a specified word in the active page of the PDF. The locations are returned as Screen Element Rectangle objects.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
word |
Text |
The word to locate in the image |
Returns
Returns a list of type Screen Element Object.
Retrieves all instances of suspicious data on the active page of the PDF.
|
Parameter |
Input Type |
Description |
|---|---|---|
|
check words in dictionary |
Boolean |
This parameter is for future use. Any value can be set. |
Returns
Returns a list of type OCR Suspicious Data.
Example
Page 3 of the PDF page includes the following text. It appears as if the word vegetables may have been crossed out.

The workflow below:
-
Sets the active page to page 3.
-
Retrieves suspicious text on the page using the Get Suspicious Data method, and stores the results in the variable List_of_OCR_Suspicious_Data (a list of variable type OCR Suspicious Data).
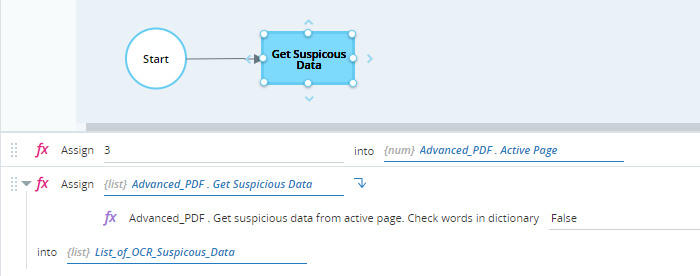
When executed, the sentence including the suspicious text is identified as suspicious. The location of the sentence is also returned.

Retrieves all text from a specified table on the active page of the PDF and stores the data in list form.
Note the following:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.
-
The table does not have to have the same number of columns in each row.
-
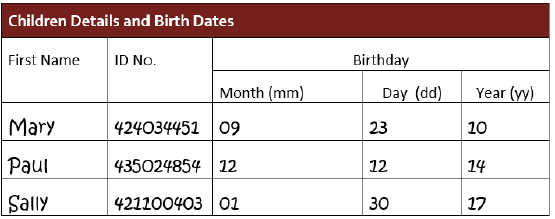
Where rows are split, data is captured as expected. (See the example below in which the sub-headers for Month, Day, and Year are captured.)
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
table number |
Number |
The number of the table on the active page of the PDF file of the Advanced PDF Object. The first table on the page is numbered 1. |
Returns
Returns a list of text, where each element of the list stores the text from one cell of the table. The list is populated by the contents of the first row of the table, then of the second row, and so on.
Example
Page 2 of the PDF includes this table.

The workflow below:
-
Sets the active page to page 2.
-
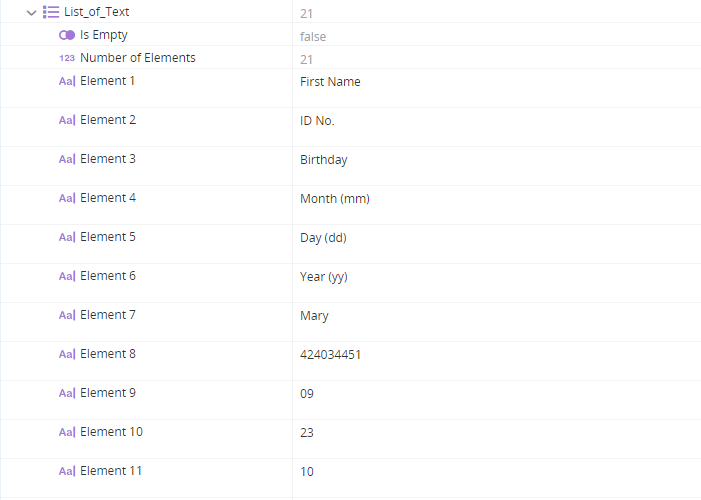
Retrieves the text from the first table on the page using the method Get Table Text as List and stores it in the variable List_of_Text (a list of variable type Text).

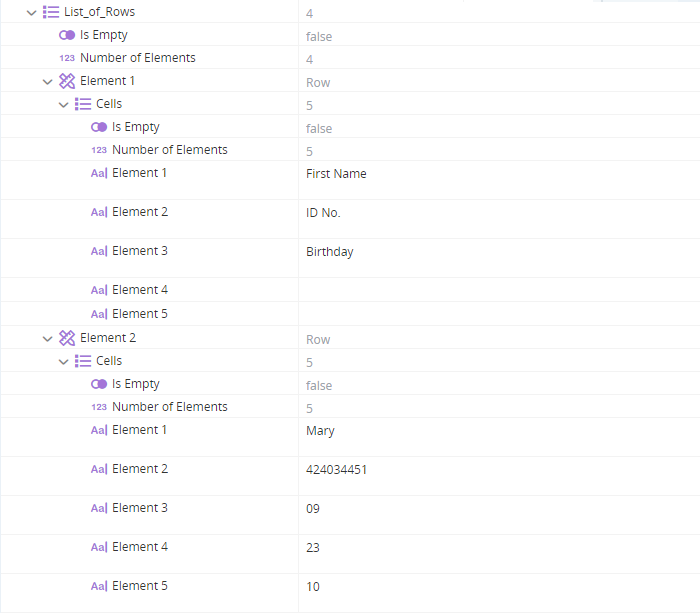
When executed, the variable List_of_Text is populated. The values of the cells in the first two rows are shown below. Note that the sub-headers Month, Day, and Year are captured.
Retrieves all text from a specified table on the active page of the PDF and stores the data in table form.
Note the following:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.
-
The table does not have to have the same number of columns in each row. The number of elements in each row will be equal to the maximum number of columns in any row. Row elements are left empty where no corresponding column exists for that row in the column.
-
Where rows are split, data may be missed. In this example, the sub-headers Month, Day, and Year are not captured.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
table number |
Number |
The number of the table on the active page of the PDF file of the Advanced PDF Object. The first table on the page is numbered 1. |
Returns
Returns a list of rows, where each element of a row stores the text from the corresponding cell of the table.
Example
Page 2 of the PDF includes this table.
The workflow below:
-
Sets the active page to page 2.
-
Retrieves the text from the first table on the page using the method Get Table Text as Table and stores it in the variable List_Of_Rows (a list of variable of type Row).
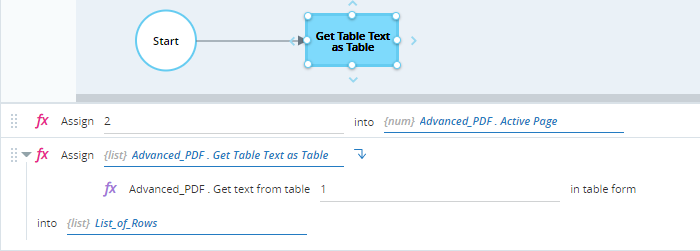
When executed, the variable List_of_Rows is populated. The values of the cells in the first two rows are shown below. Note that where rows are split, data may be missed. In this example, the sub-headers Month, Day, and Year are not captured.
Retrieves the text from a specified block on the active page of the PDF. The first block recognized on the page is numbered 1. To retrieve each word in the block individually, use Get Words from Block.
There is no way in advance to know how the blocks on a page will be numbered - the first block on the page will not necessarily be numbered 1. However, every time a PDF of the same structure is read, the corresponding blocks will always be numbered in the same way. Some trial and error may be required when choosing the block number to specify.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
block number |
The number of the text block on the active page. Numbers are not necessarily assigned to blocks in the order in which they appear on the page. |
Returns
Returns text.
Example
This example demonstrates how to capture the text in the highlighted block below on page 3 of the PDF.
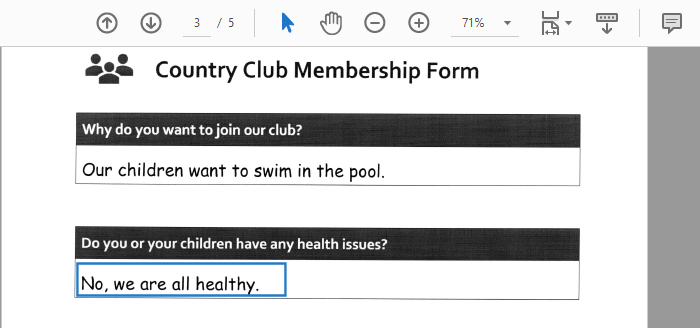
The text block is recognized as block 4 when processed. It is not possible to know in advance how blocks will be numbered, although every time the same page is processed, the blocks on the page will be numbered in the same order.
The workflow below:
-
Sets the active page to page 3.
-
Retrieves the text in block 4 using the method Get Text from Block and stores it in the Text_Var variable (of type Text).
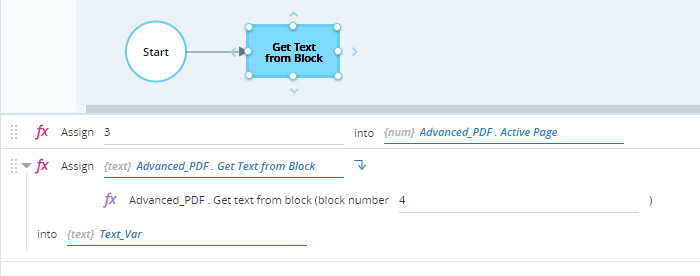
When executed, the text is written to the Text_Var variable.
Retrieves the text from the active page of the PDF. All the text on the page is returned as a single text value. To retrieve each word individually, use Get Words from Page.
Note that if the active page includes multiple blocks of text, the texts will not necessarily be returned from the top of the page to the bottom. However, every time this method is applied to a PDF file of the same layout, the texts will be returned in the same order.
Parameters
This method does not have any parameters.
Returns
Returns the text page as text. LS (line separator) and PS (paragraph separators) are included within the text - see the example below.
Example
Page 4 of the example PDF includes some legal information.

The workflow below:
-
Sets the active page to page 4.
-
Retrieves the text from the active page using the Get Text from Page method and stores it in the text variable Text_Var.
-
Writes the text to the text file at c:\temp\legal_text.txt, using the Write Text to File method.
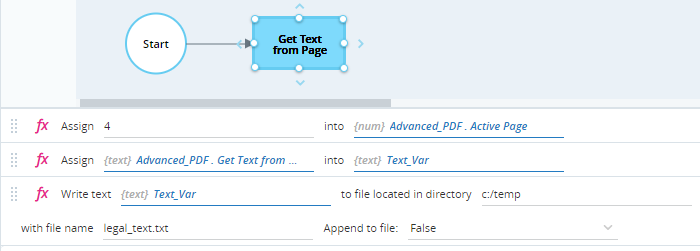
When executed, the text is written to the variable Text_Var.

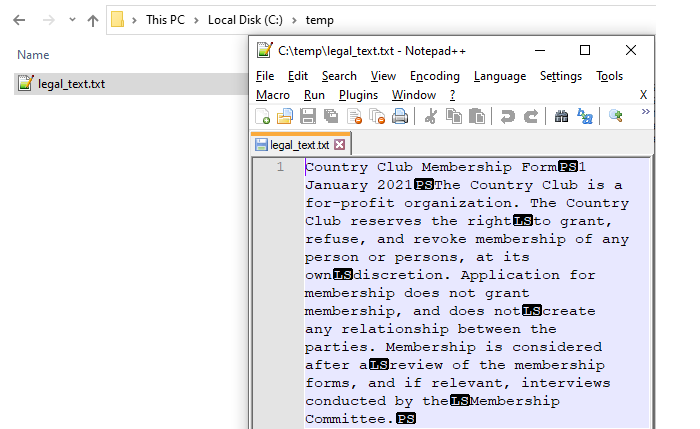
The file c:\temp\legal_text.txt is created and populated. Note the PS (paragraph separator) and LS (line separator) markers.
Retrieves all words individually from a specified block on the active page of the PDF. The first block recognized on the page is numbered 1. To retrieve all words in the block as a single text value, use Get Text from Block.
There is no way in advance to know how the blocks on a page will be numbered - the first block on the page will not necessarily be numbered 1. However, every time a PDF of the same structure is read, the corresponding blocks will always be numbered in the same way. Some trial and error may be required when choosing the block number to specify.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
block number |
The number of the text block on the active page. Numbers are not necessarily assigned to blocks in the order in which they appear on the page. |
Returns
Returns a list of type OCR Word Data Objects.
Example
This example demonstrates how to capture the text in the highlighted block below on page 3 of the PDF.
The text block is recognized as block 2 when processed. It is not possible to know in advance how blocks will be numbered, although every time the same page is processed, the blocks on the page will be numbered in the same order.
The workflow below:
-
Sets the active page to page 2.
-
Retrieves the words in block 2 using the method Get Words from Block and stores them in the OCR_Word_Data_Object variable (of type OCR Word Data Object).
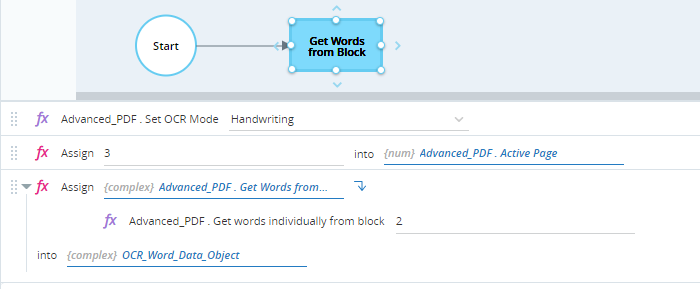
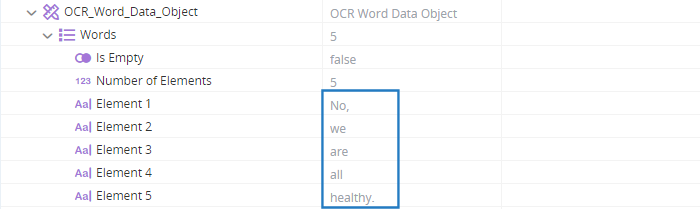
When executed, each word in that block is entered as a separate element in the OCR_Word_Data_Object variable.
Retrieve all words individually from the active page of the PDF. To retrieve all text on the page as a single text value, use Get Text from Page.
Note that if the active page includes multiple blocks of text, the texts will not necessarily be returned from the top of the page to the bottom. However, every time this method is applied to a PDF file of the same layout, the texts will be returned in the same order.
Parameters
This method does not have any parameters.
Returns
Returns a list of type OCR Word Data Object.
Example
Page 4 of the example PDF includes some legal information.
The workflow below:
-
Sets the active page to page 4.
-
Retrieves the words from the active page using the Get Words from Page method and stores it in the variable OCR_Word_Data_Object (of type OCR Word Data Object).
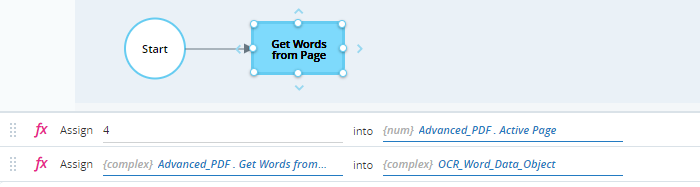
When executed, the words on the page are all listed in the variable OCR_Word_Data_Object.
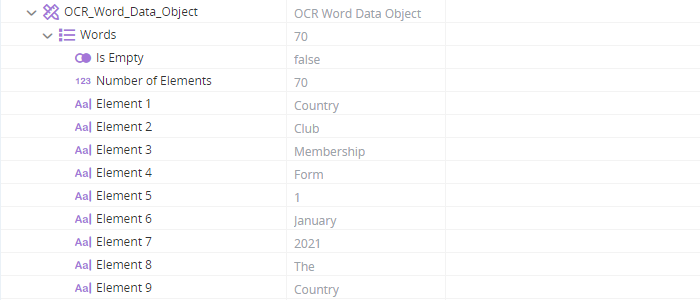
Measures the brightness of a specified rectangle of the active page. Returns a decimal ranging from 0 (black) to 100 (white). If the rectangle has regions of different colors, the brightness returned is a measure of the average brightness.
This method can be used, for example, to read values of multiple-choice test answer cards. It can also be used to check whether a box in a form has been colored or left empty.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the area to be measured for brightness (specified by its left and top parameters), and the size of that area (specified by its height and width parameters) |
Returns
Returns a decimal ranging from 0 (black) to 100 (white).
Example
The workflow below measures the brightness of the two checkbox areas below to determine whether they are selected or not.

The workflow below consists of two steps, one to measure the brightness of each checkbox.
The first step:
-
Sets the active page to page 1.
-
Sets the properties of the Screen_Element_Rectangle variable (of type Screen Element Rectangle). (See the example for Extract Rectangle as Image for instructions on how to measure these values.)
-
Uses the Measure Brightness of Rectangle method to measure the brightness of the rectangle specified by Screen_Element_Rectangle. The value is written to the decimal variable Decimal_1.
The second step:
-
Sets the properties of the Screen_Element_Rectangle_2 variable. (See the example for Extract Rectangle as Image for instructions on how to measure these values.)
-
Uses the Measure Brightness of Rectangle method to measure the brightness of the rectangle specified by Screen_Element_Rectangle_2. The value is written to the decimal variable Decimal_2.

When executed, the values of Decimal_1 and Decimal_2 are set.

Note that Brightness_1 is significantly lower than Brightness_2. This is because the second checkbox is completely empty (lighter) while the first includes a black checkmark (darker).
(Available from version 7.3 onward.)
Preloads multiple pages listed individually by page number to speed up processing of large files. Note that all methods that read data from the active page will still only read data from the active page, even if multiple pages were preloaded.
This method populates the File Name property of the Advanced PDF Object. You do not need to assign a value to the File Name property separately.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| full path | Text | The full path to the PDF file to load |
|
page numbers |
List of Numbers |
The numbers of the pages to preload |
Returns
Nothing
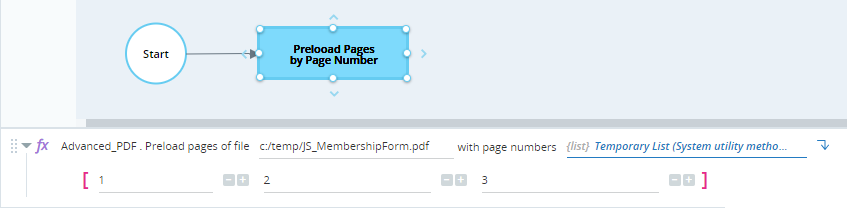
Example
The workflow below preloads pages of the file c:\temp\JS_MembershipForm.pdf. The pages to preload are specified in a temporary list.
(Available from version 7.3 onward.)
Preloads a range of pages specified by the start page number and number of pages to speed up processing of large files. Note that all methods that read data from the active page will still only read data from the active page, even if multiple pages were preloaded.
This method populates the File Name property of the Advanced PDF Object. You do not need to assign a value to the File Name property separately.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| full path | Text | The full path to the PDF file to load |
|
start page |
Number |
The page number of the first page in the range to preload |
| number of pages | Number | The number of pages to preload, including the first page in the range |
Returns
Nothing
Example
The workflow below preloads pages of the file c:\temp\JS_MembershipForm.pdf. It preloads three pages from (and including) page 1.
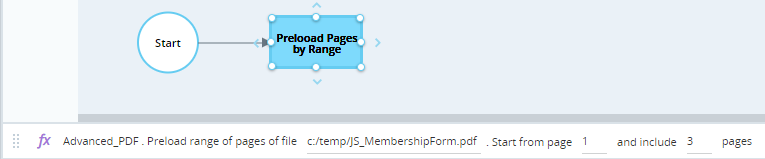
Set the OCR mode to be used for character recognition.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| mode | Text |
Select the desired mode from the drop-down list. Available values include:
|
As Fine Reader 12 only offers limited handwriting capabilities, we recommend using one of the third-party integrations for handwriting identification.
Returns
Nothing
Advanced Picture Object
Create an Advanced Picture Object variable to capture text from image files, for example, scanned forms that were hand-filled by customers.
For an example project that uses the Advanced Picture Object, see Project: Capture Data from Scanned Forms.
|
Property |
Type |
Description |
Writable |
|---|---|---|---|
| Height | Number | The height of the image in pixels | No |
| Languages | Text | The expected language(s) of the text, passed as in input to the OCR engine to improve text recognition. The default is English. |
Yes (Use Set Languages) |
| Handwriting Identification Mode | Text | The name of the handwriting style of the text, passed as in input to the OCR engine to improve text recognition. Relevant only when OCR Mode is set to Handwriting. | |
| Block Count | Number | The number of OCR blocks in the image | No |
| Table Count | Number | The number of tables in the image | No |
| OCR Mode | Text | The OCR mode to be used by the OCR engine |
Yes (Use Set OCR Mode) |
| Width | Number | The width of the image in pixels | No |
Methods
Compares the image in the Advanced Picture Object with the image in a second Advanced Picture Object.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| advanced picture object | Advanced Picture Object | The advanced picture object that stores the image for comparison |
Returns
Returns a Boolean value True only if both images are identical. Returns False if even one pixel is different.
Measures how similar the image in the Advanced Picture Object is to the image in another Advanced Picture Object. Typical use case is to compare the contents of a checkbox on a customer's form to a filled checkbox on a prepared template form.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| advanced picture object | Advanced Picture Object | The advanced picture object that stores the image for comparison |
Returns
Returns a decimal ranging from 100 (identical) to 0 (very different).
Loads the image currently in the Windows clipboard into the Advanced Picture Object.
Paramaters
This method does not have any parameters.
Returns
Nothing
Loads the image in a specified picture file into the Advanced Picture Object.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| full path | Text | The full path to the image file to load |
Returns
Nothing
Captures a screenshot of a window specified by its window handle and loads that image into the Advanced Picture Object. The specified window is activated and brought to front before the screenshot is captured.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| window handle | Number | The window handle of the window to capture and load as an image |
Returns
Nothing
Use with the Assign function to load a cropped section of the image in the Advanced Picture Object into another Advanced Picture Object. The area to crop to is specified by a Screen Rectangle Object.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the area to crop to (specified by its left and top parameters), and the size of the area to crop to (specified by its height and width paramaters) |
Returns
Nothing
Measures the brightness of a specified rectangle of the Advanced Picture Object.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the rectangle (specified by its left and top parameters), and the size of the rectangle (specified by its height and width paramaters) |
Returns
Returns a decimal ranging from 0 (white) to 100 (black).
Retrieves all words individually from a specified block of the image. The first block is numbered 1. To retrieve all words in the block as a single text value, use Get Text from Block.
There is no way in advance to know how the blocks in an image will be numbered - the first block will not neccessarily be numbered 1. However, every time an image of the same structure is read, the corresponding blocks will always be numbered in the same way. Some trial and error may be required when choosing the block number to specify.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
block number |
The number of the text block in the image. Numbers are not necessarily assigned to blocks in the order in which they appear in the image. |
Returns
Returns a list of type OCR Word Data Objects.
Retrieves the state of the checkbox in a specified rectangle in the image. Returns a text value: Checked, NotChecked, Corrected (was checked but then corrected), or Not Recognized. If OCR is not installed, NotDetected is returned.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
screen element rectangle |
The location of the top left corner of the checkbox (specified by its left and top parameters), and the size of that area (specified by its height and width paramaters) |
Retrieves the text from a specified block in the image. The first block in the image is numbered 1. To retrieve each word in the block individually, use Get Words from Block.
There is no way in advance to know how the blocks in an image will be numbered - the first block will not neccessarily be numbered 1. However, every time an image of the same structure is read, the corresponding blocks will always be numbered in the same way. Some trial and error may be required when choosing the block number to specify.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
block number |
The number of the text block in the image. Numbers are not necessarily assigned to blocks in the order in which they appear in the image. |
Returns
Returns text.
Retrieves all instances of suspicious data in the image. Optionally check suspicious words against a dictionary.
|
Parameter |
Input Type |
Description |
|---|---|---|
|
check words in dictionary |
Boolean |
Whether to use the dictionary to assist in identifying suspicious text. |
Returns
Returns a list of type OCR Suspicious Data.
Retrieves all text from a specified table in the image and stores the data in table form.
Note the following:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.
-
The table does not have to have the same number of columns in each row. The number of elements in each row will be equal to the maximum number of columns in any row. Row elements are left empty where no corresponding column exists for that row in the column.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
table number |
Number |
The number of the table in the image. The first table on the page is numbered 1. |
Returns
Returns a list of rows, where each element of a row stores the text from the corresponding cell of the table.
Retrieves all text from a specified table in the image and stores the data in list form.
Note the following:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.
-
The table does not have to have the same number of columns in each row.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
table number |
Number |
The number of the table in the image. The first table on the page is numbered 1. |
Returns
Returns a list of text, where each element of the list stores the text from one cell of the table. The list is populated by the contents of the first row of the table, then of the second row, and so on.
Retrieves the locations of all cells in a table. The first table in the image is numbered 1. The locations are returned as elements in a list of type Screen Element Rectangle. The locations of the cells in the first row are returned first in the list, followed by the cells in the second row, and so on.
Note that:
-
The table borders do not have to be visible for the table to be identified and its contents recognized.
-
The table does not have to have the same number of columns in each row.
Returns
Returns a list of type Screen Element Rectangle. Each cell is represented by one element in the list.
Retrieves the color of the text in an image. This function is intended for cases in which all text is of the same color and on a white background.
Parameters
This method has no parameters.
Returns
Returns the color as text in RGB format, for example, 34,177,176.
Retrieves the text from the image. All the text on the page is returned as a single text value. To retrieve each word individually, use Get Words from Image.
Note that if the image includes multiple blocks of text, the texts will not necessarily be returned from the top of the page to the bottom. However, every time this method is applied to an image of the same layout, the texts will be returned in the same order.
Parameters
This method does not have any parameters.
Retrieves a list of all locations of a specified word in the image. The locations are returned as Screen Element Rectangle objects.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
word |
Text |
The word to locate in the image |
Returns
Returns a list of type Screen Element Object.
Retrieves all words individually from the image. To retrieve all text on the page as a single text value, use Get Text from Image.
Note that if the active page includes multiple blocks of text, the texts will not necessarily be returned from the top of the page to the bottom. However, every time this method is applied to a PDF file of the same layout, the texts will be returned in the same order.
Parameters
This method does not have any parameters.
Returns
Returns a list of type OCR Word Data Object.
Rotate the image stored in the Advanced Picture Object clockwise by the specified angle.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
|
angle |
Number |
The angle by which to rotate the image. Valid values: 90, 180, 270 |
Returns
Nothing
Saves the image stored in the Advanced Picture Object to a specified file. When specifying the file name, you can use any of the following image file extensions: .png, .gif, .jpg, .tiff.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| full path | Text |
The full path to the image file to save. Use any one of the following file extensions: .png, .gif, .jpg, .tiff |
Returns
Nothing
Copies the image in the Advanced Picture Object to the Windows clipboard.
Parameters
This method does not have any parameters.
Returns
Nothing
Set the OCR mode to be used for character recognition.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| mode | Text |
Select the desired mode from the drop-down list. Available values include:
|
As Fine Reader 12 only offers limited handwriting capabilities, we recommend using one of the third-party integrations for handwriting identification.
Returns
Nothing
OCR Suspicious Data Object
Create an OCR Suspicious Data Object variable to store information about a single instance of suspicious data in a PDF file or image.
Note that you need to create a list variable of this type to capture all instances of suspicious data from a PDF file or image.
Properties
OCR Word Data Object
Create an OCR Word Data variable to store the list of words found using various methods of Advanced PDF Object and Advanced Picture Object variables.
Properties
Methods
Retrieve the location of a single word from the OCR Word Data variable as a Screen Element Rectangle.
Parameters
|
Parameter |
Input Type |
Description |
|---|---|---|
| index | number | The index number of the word in the OCR Word Data variable. The index number of the first element of the Word Data variable is 0. |
Returns
Returns a Screen Element Rectangle.
Example
The workflow in the example for Get Words from Page populates the variable OCR_Word_Data_Object with all words on the first page of the sample PDF page, as shown below.

The workflow below first runs the workflow from the example for Get Words from Page. It then uses the Get Word Rectangle method to populate the variable Screen_Element_Rectangle with the location of the first word in the variable OCR_Word_Data_Object.
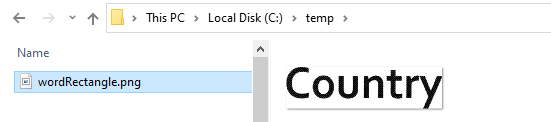
For demonstration purposes, the workflow then extracts the location specified by that screen element rectangle from the PDF file and saves it to a file wordRectangle.png.

When executed, the variable Screen_Element_Rectangle is populated with the location information about the first word in OCR_Word_Data_Object.

The file wordRectangle.png is saved and contains the first word listed in OCR_Word_Data_Object.
{kind=link}